.png?width=2000&name=SDG%20-%20Logo%20White%20(1).png)

The integration of different artifacts, objects, and data records is an important component of any project in the data and analytics field.
Thus, considering any data source in a uniform and standardized way facilitates the job of extracting and loading valuable information for the business and the different use cases. In this new story, we present a Python component that standardizes the communication between different data sources and the way we process each information stored in a data layer. In this case, we will use Snowflake, Amazon S3, and MLFlow to store our data and artifacts, but this approach is extensible and can be applied to other cases as shown in the following sections.
1. Solution Overview
In this section, we are going to explain how a solution for integrating heterogeneous information data sources in a standardized way works. Our solution explores a comprehensive data management system centered around a management entity. This manager plays a pivotal role with two key properties: one overseeing the data loading mechanism and another governing the data-saving process. Thus, our solution is capable of managing input and output operations across diverse data formats, protocols, and platforms, ensuring seamless interoperability and efficient data flow within the ecosystem.
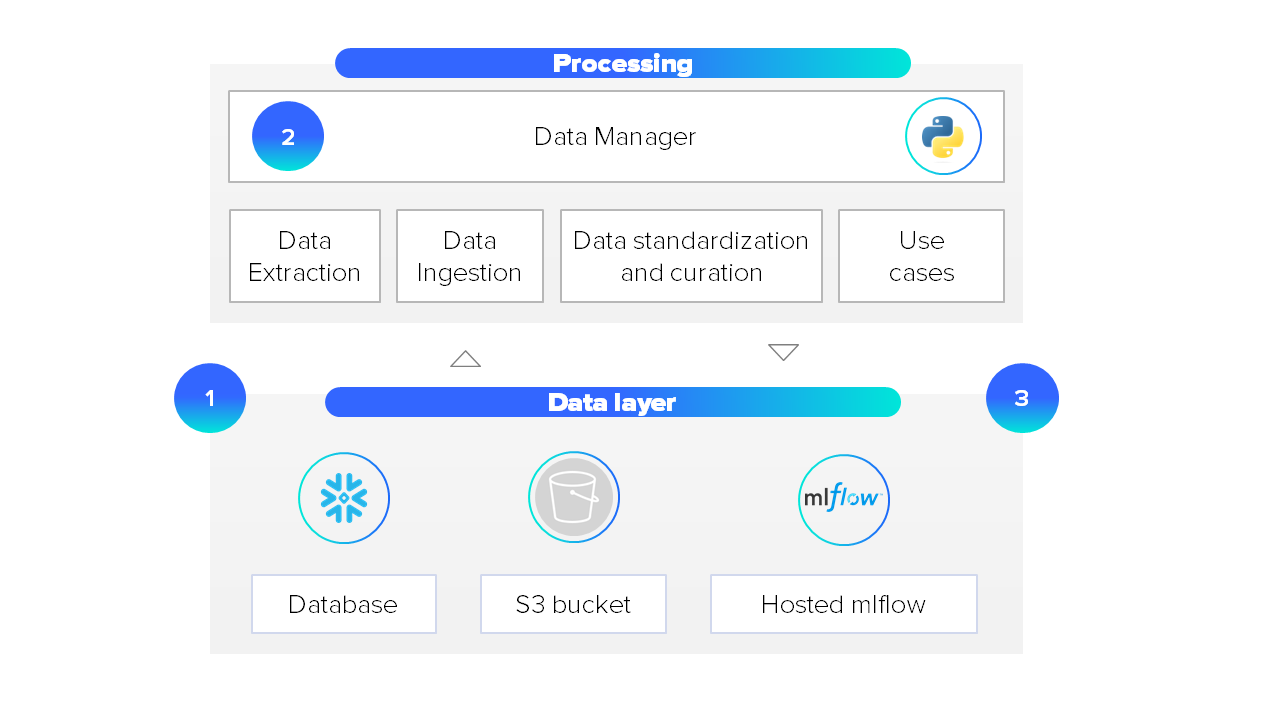
The above figure shows how our solution, developed as a Python component, works. The (1) data manager, the central piece of our implementation, pulls data stored at any of the different storage options into a processing pipeline. Then, (2) the processing pipeline processes the data that comes in this case from Snowflake, S3, or MLFlow. Finally, (3) the data manager stores the recently processed data in any of the different storage options, integrating them and making the data interchangeable.
Going deep into these properties, we uncover an intricate interplay that empowers users to seamlessly control both data retrieval and storage mechanisms. For that purpose, we are going to show how a UML class diagram can be constructed for this solution:
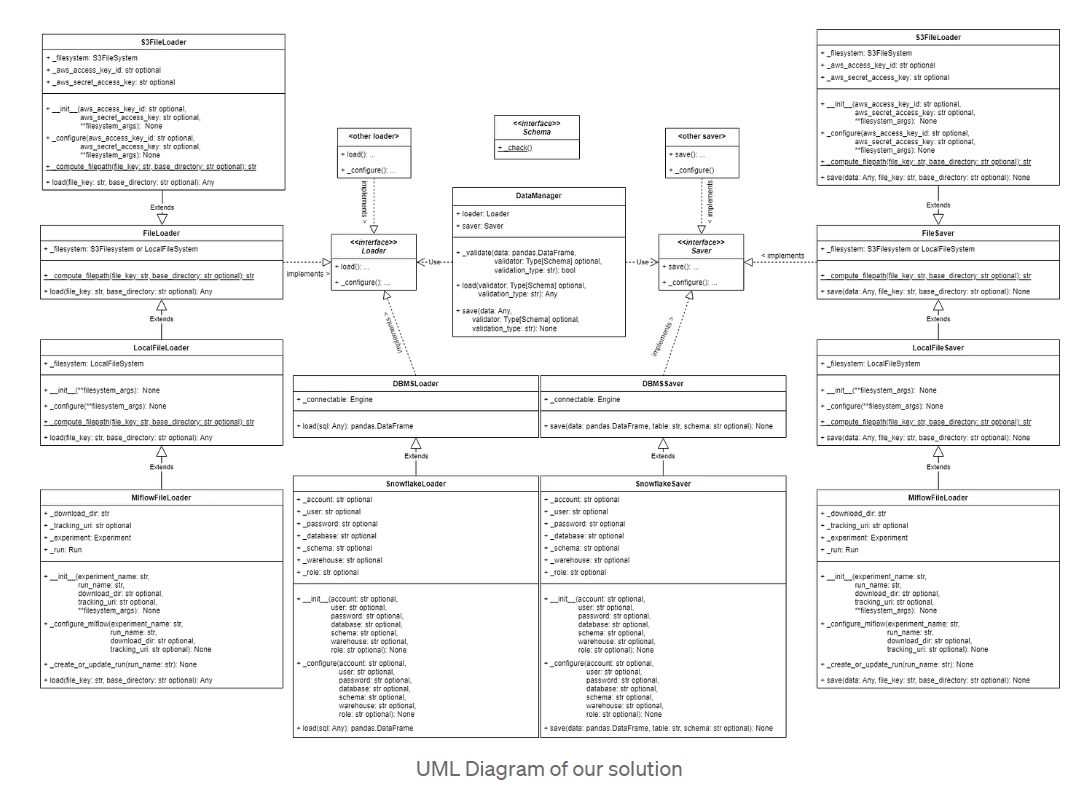
Our solution is based on four simple elements. The first one is the DataManager class, which delegates the load and save functionalities to its instantiated loader and saver attributes. The data manager class is in charge of applying the data quality checks to the data being loaded/saved. The second one is the Loader class, which is in charge of loading data from the different data sources to process it later. The third one is the Saver class, which is in charge of saving the processed data to the different data sources. Finally, both classes (loader and saver) need to be validated after and before managing the data in the data sources. For that purpose, we have a validation step implemented in the data manager that is in charge of performing the appropriate data quality checks when needed. In the following sections, we are going to describe these four elements more precisely.
The example we are going to show in this article is based on an implementation for Python, but conceptually this article is extensible to other object-oriented programming languages.
2. Components of our solution
Next, we present the different parts that our solutions are composed of. As we said, the central piece of our solution is a data manager that integrates the information coming from different data sources. Basically, in our solution, the Loader and Saver classes have to be extended with particular implementations for each data source. This implementation can be rehabilitated using data connectors, libraries, or other classes. In the following section, we will show how these connections have been implemented for DBMS, Snowflake, S3, MLFlow, and local files.
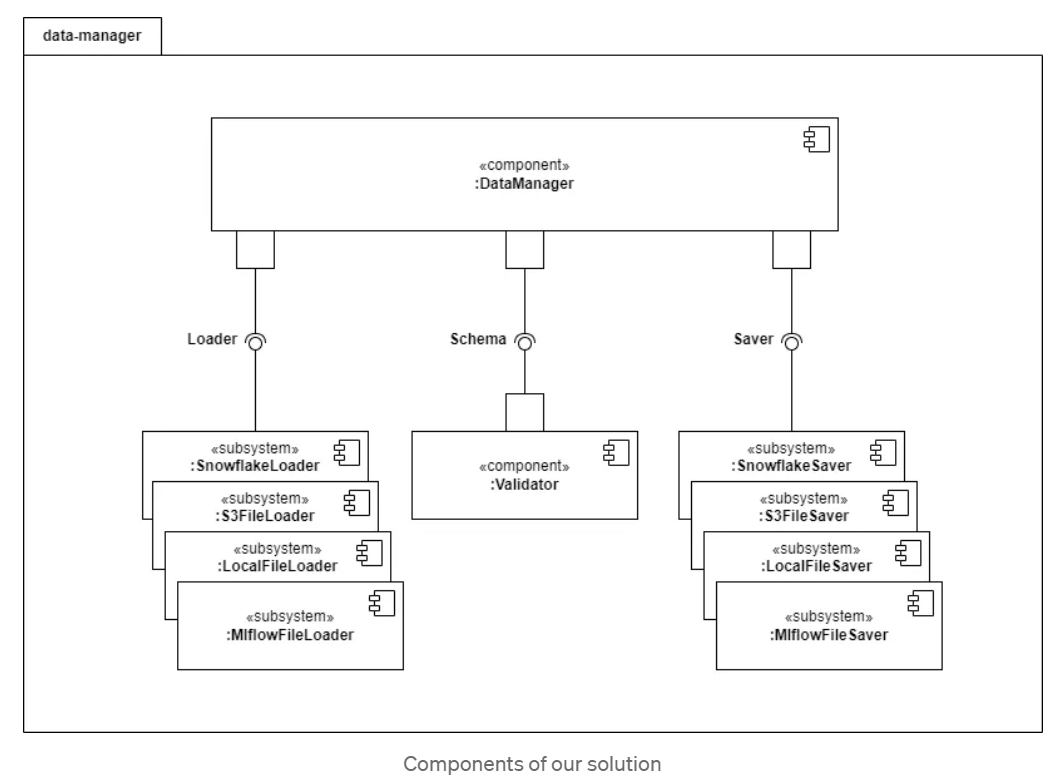
2.1. Data Managers
The DataManager class serves as the core component within our solution, functioning as a pivotal manager that facilitates interactions with various data layers specified for a project. It plays a crucial role in orchestrating the communication and operations between different components involved in handling data. The data manager is composed of three elements:
- Loader: It is in charge of extracting data from a data source using a configured loader. It also allows specifying the data quality applicability and any additional arguments relative to the loading components.
- Saver: It is in charge of storing objects and artifacts to a data source using the configured saver. This allows specifying the data quality applicability and any additional arguments relative to the saving components.
- Validator: Helping methods that apply and control the data quality checks.
In our implementation, demonstrated using Python, we provide a modular and configurable solution for handling different types of data and heterogeneous sources in complex projects.
In the following sections, we will show how each element has been implemented and we will provide details about how each data source has been used and connected.
@dataclass
class DataManager:
loader: Loader
saver: Saver
def _validate(
self,
data: pd.DataFrame,
validator: Type[Schema] | None = None,
validation_type: str = "none",
) -> bool:
if validation_type == "none" and not validator:
return True
elif not validator:
raise ValueError(
f"Missing validator for validation_type: {validation_type}"
)
elif validation_type == "all" and validator:
return validator.check(data)
elif (
validation_type.isdigit()
and int(validation_type) in range(100)
and validator
):
return validator.check(data.sample(int(validation_type)))
else:
raise ValueError(
f"Unrecognized validation type: {validation_type}. Accepted values are 'none', 'all' or integer representing the percentage of data to validate, i.e. '30'"
)
def load(
self, validator: Type[Schema] | None = None, validation_type: str = "none", **kwargs
) -> Any:
data = self.loader.load(**kwargs)
if not self._validate(
data, validator=validator, validation_type=validation_type
):
raise ValidationError("Data doesn't match given schema")
else:
return data
def save(
self, data, validator: Type[Schema] | None = None, validation_type: str = "none", **kwargs
) -> None:
if not self._validate(
data, validator=validator, validation_type=validation_type
):
raise ValidationError("Data doesn't match given schema")
else:
self.saver.save(data, **kwargs)
2.2. Data Loaders
Loader classes are responsible for loading information from the data sources dynamically during runtime. They are part of the solution we have developed and they will be invoked by the manager class. Thus, loader classes are not all used at once. Essentially, it offers a standardized way to interact with diverse data sources through Python, and they are in charge of the initialization, configuration, connection retrieval, and data fetching from the different data sources.

- DBMS: An interface for implementing Data Loaders retrieving data from Database Management Systems. It requires a connection established using the SQLAlchemy’s Python API (SQLAlchemy). Thus, it can be implemented for any of the different SQLAlchemy supported dialects (Dialects — SQLAlchemy 2.0 Documentation). In our solution, the loading of information from the DBMS is done using the Pandas Input API (Input/output — pandas 2.2.0 documentation), concretely the read_sql function, which requires an SQLAlchemy Connectable object.

- Snowflake: It uses Snowflake’s Python API (Snowflake Connector for Python) along with SQLAlchemy’s Python API for establishing connections and executing SQL queries. Specific methods are implemented to load data from Snowflake using SQL queries. To enable the connection with Snowflake we must provide, at least, the account identifier (account), the user login name (user), and the password (password), additionally, we can also provide the database name (database), the schema name (schema), the warehouse (warehouse) and the role (role) for configuring the Snowflake session. All these configurations can be indicated through environment variables as we see below. Concretely, in our solution, the loading of information from Snowflake has been developed as an extension of the DBMSLoader class.
class SnowflakeLoader(DBMSLoader):
_account: str | None = os.environ.get("SNOWFLAKE_ACCOUNT")
_user: str | None = os.environ.get("SNOWFLAKE_USER")
_password: str | None = os.environ.get("SNOWFLAKE_PASSWORD")
_database: str | None = os.environ.get("SNOWFLAKE_DATABASE")
_schema: str | None = os.environ.get("SNOWFLAKE_SCHEMA")
_warehouse: str | None = os.environ.get("SNOWFLAKE_WAREHOUSE")
_role: str | None = os.environ.get("SNOWFLAKE_ROLE")
def __init__(
self,
account: str | None = None,
user: str | None = None,
password: str | None = None,
database: str | None = None,
schema: str | None = None,
warehouse: str | None = None,
role: str | None = None,
):
self._configure(
account=account or self._account,
user=user or self._user,
password=password or self._password,
database=database or self._database,
schema=schema or self._schema,
warehouse=warehouse or self._warehouse,
role=role or self._role,
)
def _configure(
self,
account: str | None,
user: str | None,
password: str | None,
database: str | None = None,
schema: str | None = None,
warehouse: str | None = None,
role: str | None = None,
):
if not user or not account or not password:
raise ValueError(
"Missing account, user or password for snowflake."
"You can provide them as arguments or set the SNOWFLAKE_ACCOUNT, SNOWFLAKE_PASSWORD and SNOWFLAKE_USER environment variables."
)
self._connectable = create_engine(
URL(
account=account,
user=user,
password=password,
database=database,
schema=schema,
warehouse=warehouse,
role=role,
)
)
def load(self, sql, **kwargs) -> pd.DataFrame:
return super().load(sql, **kwargs)
- File: An interface for implementing Data Loaders retrieving data from files. It uses fsspec Python API (fsspec) to interact with the file system. Thus, it can be implemented for any of the different fsspec-supported file system implementations (Built-in Implementations, Other Known Implementations). In our solution, the loading of information from a file is done using the fsspec filesystem instance open method (Use a File System) plus the appropriate Python API for reading the file extension. Concretely, supported file extensions and APIs are: (i) Pandas API (Input/output — pandas 2.2.0 documentation) for reading parquet, CSVs, and excel files; (ii) JSON API (JSON encoder and decoder — Python 3.12.2 documentation) for reading JSON files; (iii) pyYAML API (PyYAML Documentation) for reading YAML files; (iv) Pickle API (pickle — Python object serialization) for reading pickle files.
class FileLoader(Loader, Protocol):
_filesystem: LocalFileSystem | S3FileSystem
@staticmethod
def _compute_filepath(file_key: str, base_directory: str | None = None) -> str: ...
def load(self, file_key: str, base_directory: str | None = None, **kwargs):
filepath = self._compute_filepath(file_key, base_directory)
if not self._filesystem.exists(filepath):
raise FileNotFoundError(f"The computed filepath {filepath} doesn't exist")
if filepath.endswith(".parquet"):
with self._filesystem.open(filepath, "rb") as f:
readed_df_or_file = pd.read_parquet(f, **kwargs)
elif filepath.endswith(".csv"):
with self._filesystem.open(filepath, "rb") as f:
readed_df_or_file = pd.read_csv(f, **kwargs)
elif filepath.endswith(".xlsx") or filepath.endswith(".xls"):
with self._filesystem.open(filepath, "rb") as f:
readed_df_or_file = pd.read_excel(f, **kwargs)
elif filepath.endswith(".json"):
with self._filesystem.open(filepath, "r", encoding="utf-8") as f:
readed_df_or_file = json.load(f)
elif filepath.endswith(".yaml") or filepath.endswith("yml"):
with self._filesystem.open(filepath, "r", encoding="utf-8") as f:
readed_df_or_file = yaml.safe_load(f)
elif filepath.endswith(".pickle") or filepath.endswith(".pkl"):
with self._filesystem.open(filepath, "rb") as f:
readed_df_or_file = pickle.load(f, **kwargs)
elif filepath.endswith(".html") or filepath.endswith(".log"):
with self._filesystem.open(filepath, "r", encoding="utf-8") as f:
readed_df_or_file = f.read()
return readed_df_or_file
- LocalFile: It uses the fsspec Python API for setting up the interface to the local file system. Specific methods are implemented to load data from files located locally. The fsspec LocalFileSystem built-in implementation provides us with the tool needed to interact with the local file system. We don’t need to provide any mandatory configuration to interact with our Local File System, even though it would accept additional file system configurations such as auto_mkdir. Concretely, in our solution, the loading of information from the local file system has been developed as an implementation of the FileLoader class.
class LocalFileLoader(FileLoader):
_filesystem: LocalFileSystem
def __init__(self, **filesystem_args):
self._configure(**filesystem_args)
def _configure(self, **filesystem_args):
self._filesystem = fsspec.filesystem("file", **filesystem_args)
@staticmethod
def _compute_filepath(file_key: str, base_directory: str | None = None) -> str:
return os.path.join(base_directory or "", file_key)
def load(self, file_key: str, base_directory: str | None = None, **kwargs) -> Any:
return super().load(file_key=file_key, base_directory=base_directory, **kwargs)
- S3File: It uses the fsspec Python API for setting up the interface to the AWS S3 storage. Specific methods are implemented to load data from files located in AWS S3 buckets. The s3fs Python API (S3Fs) filesystem implementation (one of the fsspec known implementations) exposes the filesystem-like API on top of AWS S3 storage. To enable the connection to a private AWS S3 storage, we can explicitly provide the key, secret parameters required by the S3FileSystem or use Boto’s credential methods (Credentials — Boto3 1.34.40 documentation). We can also connect as anonymous users to public AWS S3 storages setting the anon param to true. Concretely, in our solution, the loading of information from an AWS S3 storage has been developed as an implementation of the FileLoader class.
class S3FileLoader(FileLoader):
_filesystem: S3FileSystem
_aws_access_key_id: str | None = os.environ.get("AWS_ACCESS_KEY_ID")
_aws_secret_access_key: str | None = os.environ.get("AWS_SECRET_ACCESS_KEY")
def __init__(
self,
aws_access_key_id: str | None = None,
aws_secret_access_key: str | None = None,
**filesystem_args,
):
self._configure(
aws_access_key_id=aws_access_key_id or self._aws_access_key_id,
aws_secret_access_key=aws_secret_access_key or self._aws_secret_access_key,
**filesystem_args,
)
def _configure(
self,
aws_access_key_id: str | None,
aws_secret_access_key: str | None,
**filesystem_args,
):
if not aws_access_key_id or not aws_secret_access_key:
raise ValueError(
"Missing aws_secret_access_key or aws_access_key_id for s3."
"You can provide them as arguments or set the AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY environment variables."
)
self._filesystem = fsspec.filesystem(
"s3", key=aws_access_key_id, secret=aws_secret_access_key, **filesystem_args
)
@staticmethod
def _compute_filepath(file_key: str, base_directory: str | None = None) -> str:
return os.path.join("s3://", base_directory or "", file_key)
def load(self, file_key: str, base_directory: str | None = None, **kwargs) -> Any:
return super().load(file_key=file_key, base_directory=base_directory, **kwargs)
- MlflowFile: It uses the mlflow Python API (A Tool for Managing the Machine Learning Lifecycle — MLflow 2.10.2 documentation) for establishing the connection to the mlflow server (hosted locally or remotely), and retrieving artifacts from mlflow. Specific methods are implemented to load artifacts from MLFlow experiments and runs. The download_artifacts method is used to download an artifact to a file locally and then the LocalFileLoader superclass is responsible for loading the file content. To configure MLFlow connection we must provide the tracking URI (tracking_uri) (setting the environment variable MLFLOW_TRACKING_URI would also work), the experiment name (experiment_name), and the run_name (run_name) containing the artifact, additionally we can provide the download directory (download_dir) where the artifacts will be downloaded locally. Concretely, in our solution, the loading of information from Mlflow has been developed as an extension of the LocalFileLoader class.
class MlflowFileLoader(LocalFileLoader):
_download_dir: str = "tmp/mlflow"
_tracking_uri: str | None = os.environ.get("MLFLOW_TRACKING_URI")
_experiment: Experiment
_run: Run
def __init__(
self,
experiment_name: str,
run_name: str,
download_dir: str | None = None,
tracking_uri: str | None = None,
**filesystem_args,
):
super().__init__(**filesystem_args)
self._configure_mlflow(
download_dir=download_dir or self._download_dir,
tracking_uri=tracking_uri or self._tracking_uri,
experiment_name=experiment_name,
run_name=run_name,
)
def _configure_mlflow(
self,
experiment_name: str,
run_name: str,
tracking_uri: str | None,
download_dir: str | None = None,
):
if not tracking_uri:
raise ValueError(
"Missing mlflow tracking uri."
"You can provide it as an argument or set the MLFLOW_TRACKING_URI environment variable."
)
self._download_dir = download_dir or self._download_dir
self._tracking_uri = tracking_uri
self._experiment = mlflow.get_experiment_by_name(
experiment_name
) or mlflow.get_experiment(mlflow.create_experiment(experiment_name))
self._create_or_update_run(run_name)
def _create_or_update_run(self, run_name: str):
runs = mlflow.search_runs(
experiment_ids=[self._experiment.experiment_id],
filter_string=f'tags.mlflow.runName = "{run_name}"',
output_format="list",
)
run_id = runs[0].info.run_id if runs else None
with (
mlflow.start_run(
experiment_id=self._experiment.experiment_id, run_id=run_id
)
if run_id
else mlflow.start_run(
experiment_id=self._experiment.experiment_id,
run_name=run_name,
)
) as run:
self._run = run
def load(self, file_key: str, base_directory: str | None = None, **kwargs) -> Any:
artifact_key = super()._compute_filepath(file_key, base_directory)
downloaded_key = super()._compute_filepath(artifact_key, self._download_dir)
mlflow.artifacts.download_artifacts(
run_id=self._run.info.run_id,
artifact_path=artifact_key,
dst_path=self._download_dir,
)
try:
return super().load(file_key=downloaded_key, **kwargs)
finally:
if os.path.exists(self._download_dir):
shutil.rmtree(self._download_dir)
2.3. Data Savers
Saver classes are responsible for storing information dynamically during runtime. They are part of the solution we have developed and they will be invoked by the manager class. Thus, saver classes are not all used at once. Essentially, it offers a standardized way to interact with diverse data storages through Python, and they are in charge of the initialization, configuration, connection retrieval, and data saving to the different data storages. We might have various implementations of saver classes for different data storages such as the following ones:

- DBMS: An interface for implementing Data Savers storing data in a Database Management Systems. It requires a connection established using the SQLAlchemy’s Python API (SQLAlchemy). Thus, it can be implemented for any SQLAlchemy-supported dialects (Dialects — SQLAlchemy 2.0 Documentation). In our solution, the saving of information to a DBMS is done using the Pandas Output API (Input/output — pandas 2.2.0 documentation), concretely the pandas DataFrame to_sql method, that requires an SQLAlchemy Connectable object.
class DBMSSaver(Saver, Protocol):
_connectable: Engine
def save(
self, data: pd.DataFrame, table: str, schema: str | None = None, **kwargs
) -> None:
with self._connectable.connect() as con:
data.to_sql(
name=table,
con=con,
schema=schema,
index=False,
**kwargs,
)
- Snowflake: It uses Snowflake’s Python API (Snowflake Connector for Python) along with SQLAlchemy’s Python API for establishing connections and saving pandas DataFrames to SQL tables. Specific methods are implemented to save data to Snowflake tables. To enable the connection with Snowflake we must provide, at least, the account identifier (account), the user login name (user), and the password (password), additionally, we can also provide the database name (database), the schema name (schema), the warehouse (warehouse) and the role (role) for configuring the Snowflake session. All these configurations can be configured through environment variables as we see below. Concretely, in our solution, the saving of information to Snowflake has been developed as an implementation of the DBMSSaver class.
class SnowflakeSaver(DBMSSaver):
_account: str | None = os.environ.get("SNOWFLAKE_ACCOUNT")
_user: str | None = os.environ.get("SNOWFLAKE_USER")
_password: str | None = os.environ.get("SNOWFLAKE_PASSWORD")
_database: str | None = os.environ.get("SNOWFLAKE_DATABASE")
_schema: str | None = os.environ.get("SNOWFLAKE_SCHEMA")
_warehouse: str | None = os.environ.get("SNOWFLAKE_WAREHOUSE")
_role: str | None = os.environ.get("SNOWFLAKE_ROLE")
def __init__(
self,
account: str | None = None,
user: str | None = None,
password: str | None = None,
database: str | None = None,
schema: str | None = None,
warehouse: str | None = None,
role: str | None = None,
):
self._configure(
account=account or self._account,
user=user or self._user,
password=password or self._password,
database=database or self._database,
schema=schema or self._schema,
warehouse=warehouse or self._warehouse,
role=role or self._role,
)
def _configure(
self,
account: str | None,
user: str | None,
password: str | None,
database: str | None = None,
schema: str | None = None,
warehouse: str | None = None,
role: str | None = None,
):
if not user or not account or not password:
raise ValueError(
"Missing account, user or password for snowflake."
"You can provide them as arguments or set the SNOWFLAKE_ACCOUNT, SNOWFLAKE_PASSWORD and SNOWFLAKE_USER environment variables."
)
self._connectable = create_engine(
URL(
account=account,
user=user,
password=password,
database=database,
schema=schema,
warehouse=warehouse,
role=role,
)
)
def save(
self, data: pd.DataFrame, table: str, schema: str | None = None, **kwargs
) -> None:
super().save(data, table=table, schema=schema, **kwargs)
- File: An interface for implementing Data Savers storing data to files. It uses fsspec Python API (fsspec) to interact with the file system. Thus, it can be implemented for any of the different fsspec-supported file system implementations (Built-in Implementations, Other Known Implementations). In our solution, the saving of information to a file is done using the fsspec filesystem instance open method (Use a File System) plus the appropriate Python API for writing to the file extension. Concretely, supported file extensions and APIs are: (i) Pandas API (Input/output — pandas 2.2.0 documentation) for writing parquet, CSVs, and excel files; (ii) JSON API (JSON encoder and decoder — Python 3.12.2 documentation) for writing JSON files; (iii) pyYAML API (PyYAML Documentation) for writing YAML files; (iv) Pickle API (pickle — Python object serialization) for writing pickle files; (v) Matplotlib API for writing figures to png, jpeg or svg files.
class FileSaver(Saver, Protocol):
_filesystem: LocalFileSystem | S3FileSystem
@staticmethod
def _compute_filepath(file_key: str, base_directory: str | None = None) -> str: ...
def save(self, data, file_key: str, base_directory: str | None = None, **kwargs) -> None:
filepath = self._compute_filepath(file_key, base_directory)
if filepath.endswith(".parquet") and isinstance(data, pd.DataFrame):
with self._filesystem.open(filepath, "wb") as f:
data.to_parquet(f, index=False, **kwargs)
elif filepath.endswith(".csv") and isinstance(data, pd.DataFrame):
with self._filesystem.open(filepath, "wb") as f:
data.to_csv(f, index=False, **kwargs)
elif (filepath.endswith(".xlsx") or filepath.endswith(".xls")) and isinstance(
data, pd.DataFrame
):
with self._filesystem.open(filepath, "wb") as f:
data.to_excel(f, index=False, **kwargs)
elif (filepath.endswith(".pickle") or filepath.endswith(".pkl")) and isinstance(
data, pd.DataFrame
):
with self._filesystem.open(filepath, "wb") as f:
data.to_pickle(f, **kwargs)
elif filepath.endswith(".json") and isinstance(data, dict):
with self._filesystem.open(filepath, "w", encoding="utf-8") as f:
json.dump(data, f, **kwargs)
elif (filepath.endswith(".yaml") or filepath.endswith("yml")) and isinstance(
data, dict
):
with self._filesystem.open(filepath, "w", encoding="utf-8") as f:
yaml.dump(data, f, **kwargs)
elif filepath.endswith(".pickle") or filepath.endswith(".pkl"):
with self._filesystem.open(filepath, "wb") as f:
pickle.dump(data, f, **kwargs)
elif filepath.endswith(".html") or filepath.endswith(".log"):
with self._filesystem.open(filepath, "w", encoding="utf-8") as f:
f.write(data, **kwargs)
elif (
filepath.endswith(".png")
or filepath.endswith(".jpeg")
or filepath.endswith(".svg")
) and issubclass(type(data), FigureBase):
with self._filesystem.open(filepath, "wb") as f:
data.savefig(f, **kwargs)
- LocalFile: It uses the fsspec Python API for setting up the interface to the local file system. Specific methods are implemented to save data to local files. The fsspec LocalFileSystem built-in implementation provides us with the tool to interact with the local file system. We don’t need to provide any mandatory configuration to interact with our Local File System, even though it is highly recommended to include auto_mkdir param to be able to write files to brand new directories. Concretely, in our solution, the saving of information to local files has been developed as an implementation of the FileSaver class.
class LocalFileSaver(FileSaver):
_filesystem: LocalFileSystem
def __init__(self, **filesystem_args):
self._configure(**filesystem_args)
def _configure(self, **filesystem_args):
self._filesystem = fsspec.filesystem("file", **filesystem_args)
@staticmethod
def _compute_filepath(file_key: str, base_directory: str | None = None) -> str:
return os.path.join(base_directory or "", file_key)
def save(self, data, file_key: str, base_directory: str | None = None, **kwargs) -> None:
filepath = self._compute_filepath(file_key, base_directory)
if (
"auto_mkdir" not in self._filesystem.__dict__.keys()
and not self._filesystem.exists(filepath)
):
raise ValueError("Specified filepath doesn't exist.")
super().save(data, file_key=file_key, base_directory=base_directory, **kwargs)
- S3File: It uses the fsspec Python API for setting up the interface to the AWS S3 storage. Specific methods are implemented to save data to files uploaded to AWS S3 buckets. The s3fs Python API (S3Fs) filesystem implementation (one of the fsspec known implementations) exposes the filesystem-like API on top of AWS S3 storage. To enable the connection to a private AWS S3 storage, we can explicitly provide the key, secret parameters required by the S3FileSystem or use boto’s credential methods (Credentials — Boto3 1.34.40 documentation). We can also connect as anonymous users to public AWS S3 storages setting the anon param to true. Concretely, in our solution, the saving of information to an AWS S3 storage has been developed as an implementation of the FileSaver class.
class S3FileSaver(FileSaver):
_filesystem: S3FileSystem
_aws_access_key_id: str | None = os.environ.get("AWS_ACCESS_KEY_ID")
_aws_secret_access_key: str | None = os.environ.get("AWS_SECRET_ACCESS_KEY")
def __init__(
self,
aws_access_key_id: str | None = None,
aws_secret_access_key: str | None = None,
**filesystem_args,
):
self._configure(
aws_access_key_id=aws_access_key_id or self._aws_access_key_id,
aws_secret_access_key=aws_secret_access_key or self._aws_secret_access_key,
**filesystem_args,
)
def _configure(
self,
aws_access_key_id: str | None,
aws_secret_access_key: str | None,
**filesystem_args,
):
if not aws_access_key_id or not aws_secret_access_key:
raise ValueError(
"Missing aws_secret_access_key or aws_access_key_id for s3."
"You can provide them as arguments or set the AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY environment variables."
)
self._filesystem = fsspec.filesystem(
"s3", key=aws_access_key_id, secret=aws_secret_access_key, **filesystem_args
)
@staticmethod
def _compute_filepath(file_key: str, base_directory: str | None = None) -> str:
return os.path.join("s3://", base_directory or "", file_key)
def save(self, data, file_key: str, base_directory: str | None = None, **kwargs) -> None:
return super().save(
data, file_key=file_key, base_directory=base_directory, **kwargs
)
- MlflowFile: It uses the mlflow Python API (A Tool for Managing the Machine Learning Lifecycle — MLflow 2.10.2 documentation) for establishing the connection to the mlflow server (hosted locally or remotely), and uploading artifacts to mlflow. Specific methods are implemented to save artifacts to MLflow experiments and runs. The save method from the LocalFileSaver superclass stores the object to a file locally and then the mlflow log_artifact method is used to upload the previously saved file to mlflow. To configure MLflow we must provide the MLflow tracking URI (tracking_uri) (setting the environment variable MLFLOW_TRACKING_URI would also work), the experiment name (experiment_name), and the run_name (run_name) containing the artifact, additionally we can provide the download_dir where the artifacts will be temporarily stored locally. Concretely, in our solution, the saving of information to Mlflow has been developed as an extension of the LocalFileSaver class.
class MlflowFileSaver(LocalFileSaver):
_download_dir: str = "tmp/mlflow"
_tracking_uri: str | None = os.environ.get("MLFLOW_TRACKING_URI")
_experiment: Experiment
_run: Run
def __init__(
self,
experiment_name: str,
run_name: str,
download_dir: str | None = None,
tracking_uri: str | None = None,
**filesystem_args,
):
super().__init__(**{**filesystem_args, **{"auto_mkdir": True}})
self._configure_mlflow(
download_dir=download_dir or self._download_dir,
tracking_uri=tracking_uri or self._tracking_uri,
experiment_name=experiment_name,
run_name=run_name,
)
def _configure_mlflow(
self,
experiment_name: str,
run_name: str,
tracking_uri: str | None = None,
download_dir: str | None = None,
):
if not tracking_uri:
raise ValueError(
"Missing mlflow tracking uri."
"You can provide it as an argument or set the MLFLOW_TRACKING_URI environment variable."
)
self._download_dir = download_dir or self._download_dir
self._tracking_uri = tracking_uri or self._tracking_uri
self._experiment = mlflow.get_experiment_by_name(
experiment_name
) or mlflow.get_experiment(mlflow.create_experiment(experiment_name))
self._create_or_update_run(run_name)
def _create_or_update_run(self, run_name: str):
runs = mlflow.search_runs(
experiment_ids=[self._experiment.experiment_id],
filter_string=f'tags.mlflow.runName = "{run_name}"',
output_format="list",
)
run_id = runs[0].info.run_id if runs else None
with (
mlflow.start_run(
experiment_id=self._experiment.experiment_id, run_id=run_id
)
if run_id
else mlflow.start_run(
experiment_id=self._experiment.experiment_id,
run_name=run_name,
)
) as run:
self._run = run
def save(self, data, file_key: str, base_directory: str | None = None, **kwargs) -> None:
artifact_key = super()._compute_filepath(file_key, base_directory)
artifact_path = os.path.dirname(artifact_key)
downloaded_key = super()._compute_filepath(artifact_key, self._download_dir)
super().save(data, file_key=downloaded_key, **kwargs)
try:
with mlflow.start_run(self._run.info.run_id):
mlflow.log_artifact(downloaded_key, artifact_path=artifact_path)
finally:
if os.path.exists(self._download_dir):
shutil.rmtree(self._download_dir)
self._create_or_update_run(self._run.info.run_name)
2.4. Validators
The validation is enabled only for DataFrame objects. Classical schemas are a good approach when it comes to validating tabular data. In our solution, we’ve defined a base Schema class using Pydantic in Python. This schema class has a class method called `check`, which requires a pandas DataFrame as input and validates that all the rows can be validated with the pydantic.BaseModel.model_validate() method. This ensures column naming validation plus data format for each column, and also it is possible to define expected values, range constraints, or regexp constraints. Just by inheriting the Schema class, we can build custom schemas with custom constraints.

Conclusions
In conclusion, the integration of diverse data sources and artifacts within a standardized framework is paramount for any project in the realm of data and analytics. The Python component presented in this narrative exemplifies an effective approach to achieving this integration seamlessly. By employing a central data manager, accompanied by a robust processing pipeline, our solution streamlines the handling of data from varied sources such as Snowflake, Amazon S3, and MLFlow. This not only ensures consistency in data communication but also facilitates interoperability across different platforms and protocols.
The DataManager, Loader, and Saver classes, along with their respective functionalities, elucidate the systematic approach adopted in managing data retrieval, processing, and storage. The incorporation of data quality checks at crucial junctures underscores the commitment to data integrity and reliability. While this narrative focuses on a Python implementation, the conceptual solution presented here is adaptable to other object-oriented programming languages, thereby extending its utility across diverse technological landscapes. By embracing this standardized approach to data integration, organizations can harness the full potential of their data assets, enabling informed decision-making and driving business success in an increasingly data-centric world.
Authors
David Rodríguez Lores
Data Scientist, SDG Group
Ángel Mora
Machine Learning archited, SDG Group



















