.png?width=2000&name=SDG%20-%20Logo%20White%20(1).png)
Empower data governance with unified lineage tracking
Welcome to TechStation, SDG's hub for exploring cutting-edge innovations in data and analytics! In this article, we delve into the powerful new lineage tracking capabilities of Azure Databricks Unity Catalog, integrated with Microsoft Purview. Discover how this feature enhances visibility, compliance, and operational efficiency, revolutionizing how organizations manage data governance.
Are you looking for something else? Check all of our content here.

As a data architect, I know firsthand the challenges of managing and governing vast amounts of data across cloud-native environments.
Data is at the heart of decision-making, innovation, and compliance; yet, without clear visibility into its movement and transformations, organizations face roadblocks.
This is why I am excited to dive into one of the most promising advancements in data governance this year: lineage tracking for Azure Databricks Unity Catalog integrated with Microsoft Purview.
This feature isn’t just a technical enhancement; it’s a strategic leap forward in empowering data teams to build trust, ensure compliance, and operate efficiently.
Let’s explore what this means for data professionals and how to harness this new capability effectively.

Understanding Data Lineage: more than just a map
At its core, data lineage is the ability to track data’s path — where it comes from, how it’s transformed, and where it goes.
But the implications go deeper. Data lineage gives context, supports accountability, and provides the transparency needed for informed decision-making.
For data architects and teams, answering questions like “Who transformed this data?” or “Why does this report show different numbers from the source data?” becomes simpler and quicker.
Azure Databricks Unity Catalog introduces a powerful way to visualize how data moves through notebooks, from the moment it is ingested to its final processed state.
More details in the official documentation to see how to capture and view data lineage using Unity Catalog.
With Microsoft Purview, this lineage is not just tracked but displayed in an integrated (with external non-Databricks services), user-friendly way, making it possible to connect the dots between datasets, transformations, and outputs across the organization.
Why is this development significant?
Before this feature, tracking data lineage within complex, multi-cloud architectures often required a patchwork of tools and processes.
The result? Fragmented views of data flows, make it difficult to piece together a comprehensive understanding.
This new integration changes the game by providing:
- End-to-End Visibility: Unified views of how data flows through Databricks notebooks and other parts of the Azure ecosystem.
- Enhanced Auditability: A clear, chronological map of data movements and transformations helps identify when and how data was modified.
- Operational Confidence: Quick detection of issues and streamlined troubleshooting when data discrepancies arise.
Prerequisites for enabling lineage tracking in Microsoft Purview
To make full use of lineage tracking for Azure Databricks Unity Catalog, you’ll need a few things set up beforehand:
1. Active Azure subscription and Microsoft Purview instance
Ensure that your organization has an active Azure subscription and a configured Microsoft Purview account. This setup forms the baseline for running scans and capturing metadata.
2. Unity catalog system schema
One key requirement is enabling the system.access schema within Unity Catalog. This schema houses lineage metadata, so activating it is crucial for extracting lineage data. More details in the official documentation on how to enable system table schemas. A POST API call will be required where you will need to specify a PAT token, the workspace and metastore ids. If the system schema is enabled successfully, result code 200 is returned.

3. User permissions
To grant access, a user that is both a metastore admin and an account admin must grant USE and SELECT permissions on the system schemas. Your scanning account should have SELECT privileges on system tables:
system.access.table_lineagesystem.access.column_lineage
These permissions ensure that Microsoft Purview can fetch comprehensive lineage data during scans.

How to capture Lineage Data: a step-by-step guide
Enabling lineage tracking during a Microsoft Purview scan involves a few straightforward steps. Here’s a quick breakdown for those looking to get started:
- Set Up a Scan in Purview: Begin by registering Azure Databricks as a data source within Microsoft Purview and configuring the integration runtime as you would for any standard scan.
- Toggle Lineage Extraction: During the configuration phase, make sure to set the Lineage Extraction option to “On”. This setting is critical for enabling Purview to gather lineage information during the scan.
- Run the Scan: Once everything is set up, execute the scan and let Purview work its magic. Take a break or grab a coffee as Purview compiles and displays lineage data in the Data Map.

Turn on Lineage Extraction toggle
Comparing Lineage Views: Azure Databricks vs. Microsoft Purview
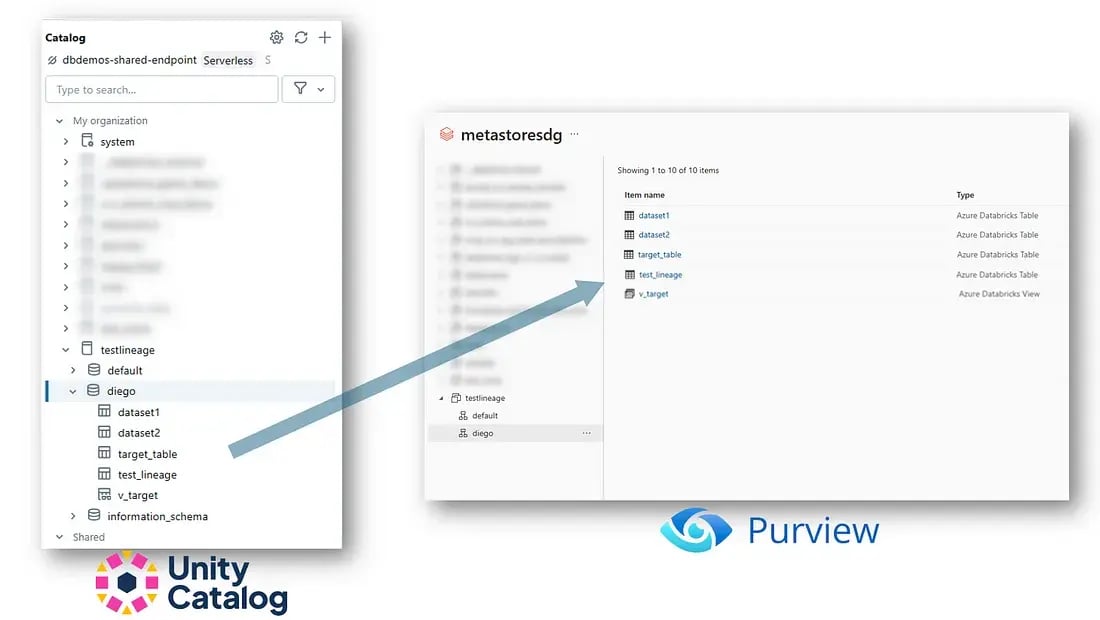
When the scan completes Azure Databricks Unity Catalog entries appear in the Microsoft Purview Data Map.
But why is this significant? Let’s compare how each platform displays lineage data:
1. Databricks Unity Catalog Lineage View
This showcases dependencies, transformations and the flow of data between different stages in your analytics process. It’s perfect for understanding how data has been manipulated within a specific environment and is essential for developers and analysts working within Databricks.

Databricks Unity Catalog Lineage View
2. Microsoft Purview Lineage View
Microsoft Purview’s view is broader. It extends beyond a single notebook to display a cohesive, visual map of data movement across different data catalogs. This capability allows you to track a piece of data from its origin in a data lake, through transformations in Databricks, and to its final state in dashboards or reports. Such comprehensive insight can drastically reduce the time it takes to trace issues and maintain data quality.

Databricks Unity Catalog Lineage View
Future Outlook: What’s Next for Azure Databricks Lineage?
Currently, the focus is on capturing lineage at the notebook level.
Microsoft and Azure Databricks are collaborating to bring lineage tracking for jobs and pipelines, expanding the ability to trace data as it moves through more automated, complex workflows.
This expansion will further reinforce an organization’s capability to:
- Maintain compliance across data pipelines.
- Gain deeper insights into data dependencies.
- Enhance collaboration between teams responsible for different parts of the data lifecycle.
KEY POINTS
- While in Unity Catalog lineage is at column level, in Purview the propagated lineage is at table level
- Unity Catalog is able to trace (and consequently propagate in Purview) the lineage of transformations performed both in SQL and PySpark
- I am still trying out the lineage tracing features in Unity Catalog — PowerBi (for example when a table is used by a report in PowerBi). Updates on this point will follow, stay tuned
Final thoughts
For data architects and governance teams, the introduction of lineage tracking for Azure Databricks Unity Catalog in Microsoft Purview is more than a technical feature — it’s a crucial step toward building a robust, transparent, and compliant data infrastructure.
With these tools, we gain not just operational efficiency but the confidence that comes with knowing our data is traceable, trustworthy, and aligned with governance standards.
Curious to explore lineage tracking for your data governance needs? Contact us to learn more!