.png?width=2000&name=SDG%20-%20Logo%20White%20(1).png)

Technical Context 🌐
The allure of cloud data platforms is undeniable: scalability, elasticity, and a cost-effective path to data management nirvana. Yet, a significant hurdle often stands in the way — the substantial investment made in building and certifying on-premise data pipelines. Dismissing these proven (but tired) workhorses feels wasteful, especially when clients have invested significant resources in their development and ongoing maintenance.
Further complicating matters, the migration process itself can be a tedious affair. Many tasks involve repetitive, manual efforts, such as meticulously mapping thousands of field names between source and target systems. These manual processes are not only time-consuming but also prone to human error. Typos, missed configurations, and inconsistencies can easily creep in, jeopardizing the entire migration effort.
The challenge 🧠
Recognizing this challenge, we at SDG embarked on a mission to streamline cloud data migrations. We assembled a team of our most experienced data architects, leveraging our 30 years of expertise in data integration. Through a series of focused discussions, we identified a critical need: automation.
This led to the development of Booster, a robust framework designed to automate the most laborious aspects of data pipeline migration.
![]()
Booster tackles the repetitive tasks, freeing up team’s valuable time and expertise for more strategic endeavors. Additionally, by capturing and codifying this automation knowledge, Booster ensures consistency and reusability across future migrations, accelerating the entire process.
But Booster’s power doesn’t stop there. With each successful migration project, Booster grows more intelligent. We continuously refine its automation capabilities based on encountered challenges and data variations. This ongoing learning cycle ensures that Booster becomes increasingly adept at handling even the most complex legacy pipelines, making future migrations even smoother and more accurate. As a result, Booster transforms from a valuable tool to a true partner in the cloud migration journey.
What can I do with Booster? ▶️
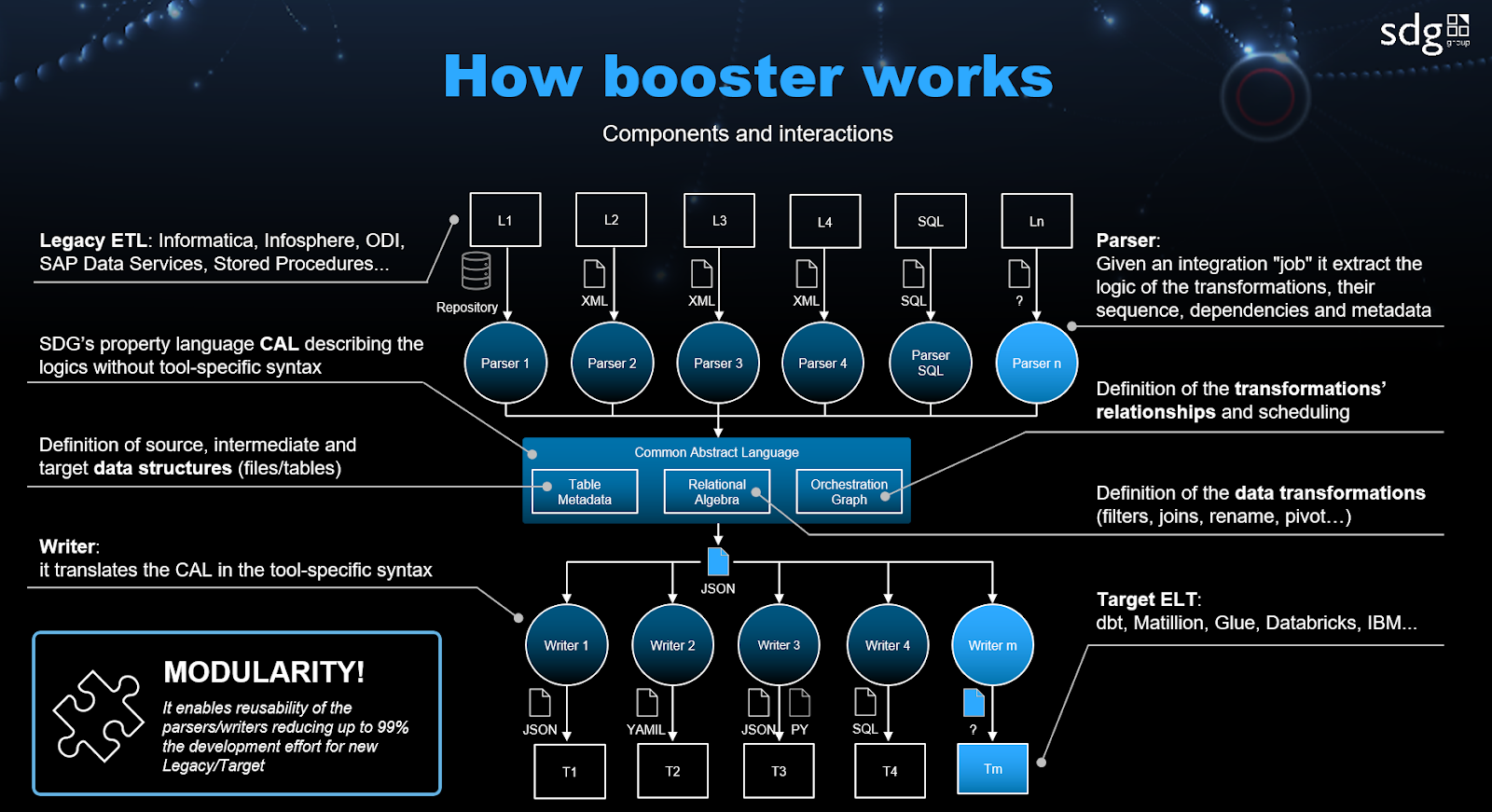
How Booster works ⚙️
Let’s describe a bit the ideas behind the accelerator.
Booster components 🏗
Built with Python, Booster boasts a modular and plug-in-oriented architecture, making it adaptable and efficient. Booster’s components are classified in Parsers, Writers, Transformers and CAL (Common Abstract Language)
Parsing the past 🔙
Imagine throwing a black box at Booster containing your old ETL logic. Its parsers, the first line, delve into the box, meticulously extracting the essence of your data transformations, their order, dependencies, and valuable metadata. They essentially translate the cryptic language of your legacy system into a format Booster understands.
Writing the Future ⏭
Once the past is parsed, Booster sets its sights on the future. Its writers, armed with the extracted information, act as language experts, fluently translating Booster’s internal representation (CAL) into the specific syntax of your target system. This ensures seamless integration with your new technology.
Transforming with Automation ✨
But Booster doesn’t stop there. It understands that sometimes, direct translation isn’t enough. This is where its transformers come in. These clever tools automate the process of refactoring your data pipelines, introducing customizations to fit the specific requirements of your new system. Think of them as fine-tuning the engine for optimal performance in its new environment.
The 💖 of the Machine: CAL
At the core of Booster lies CAL, the Common Abstract Language; a universal translator, agnostic to the specifics of any individual system. It represents metadata, data transformations (using relational algebra for a clear and standardized approach), and orchestration logic (defining dependencies, conditions, loops, error management, even alerting and much more). CAL acts as the common ground where Booster parses the past, plans the future, and guides the transformers to make it all happen.
Features update plan: How do we keep Booster at pace?
SDG is committed to continuously improving Booster based on valuable customer feedback. We prioritize keeping Booster vendor and tool agnostic. This ensures maximum flexibility for users, allowing them to freely migrate between different cloud platforms and data integration tools. However, SDG also keeps strong partnerships with major cloud service and data analytics providers like AWS, GCP, Snowflake, Matillion, dbt, SAP, Databricks, IBM… This means you can leverage Booster with confidence, knowing it will seamlessly integrate with the most popular industry solutions. In the coming months, we expect to expand Booster's compatibility to encompass an even greater range of market-leading ETL targets.